Hi, I’m Hien! I’m a doctoral student in the MEAM department and GRASP Lab at University of Pennsylvania. I work at DAIR Lab under my supervisor Michael Posa.
I graduated with a Bachelor of Mechanical Engineering (specialized in Robotics and Mechatronics) from Nanyang Technological University in Singapore. Before starting my PhD at Penn, I worked at Eureka Robotics as Robotics Engineer for 3 years, building Archimedes Robot, an ultra-precise optics handling robotic system.
Non-prehensile manipulation of diverse objects remains a core challenge in robotics, driven by unknown physical properties and the complexity of contact-rich interactions. Recent advances in contact-implicit model predictive control (CI-MPC), with contact reasoning embedded directly in the trajectory optimization, have shown promise in tackling the task efficiently and robustly, yet demonstrations have been limited to narrowly curated examples. In this work, we showcase the broader capabilities of CI-MPC through precise planar pushing tasks over a wide range of object geometries, including multi-object domains. These scenarios demand reasoning over numerous inter-object and object-environment contacts to strategically manipulate and de-clutter the environment, challenges that were intractable for prior CI-MPC methods. To achieve this, we introduce Consensus Complementarity Control Plus (C3+), an enhanced CI-MPC algorithm integrated into a complete pipeline spanning object scanning, mesh reconstruction, and hardware execution. Compared to its predecessor C3, C3+ achieves substantially faster solve times, enabling real-time performance even in multi-object pushing tasks. On hardware, our system achieves overall 98% success rate across 33 objects, reaching pose goals within tight tolerances. The average time-to-goal is approximately 0.5, 1.6, 3.2, and 5.3 minutes for 1-, 2-, 3-, and 4-object tasks, respectively.
@article{Bui2026,title={Push Anything: Single- and Multi-Object Pushing From First Sight with Contact-Implicit MPC},author={Bui, Hien and Gao, Yufeiyang and Yang, Haoran and Cui, Eric and Mody, Siddhant and Acosta, Brian and Felix, Thomas Stephen and Bianchini, Bibit and Posa, Michael},journal={Under Review},year={2025},month=oct,doi={10.48550/arXiv.2510.19974},url={https://arxiv.org/abs/2510.19974},}
Enhancing Task Performance of Learned Simplified Models via Reinforcement Learning
Hien Bui and Michael Posa
In IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, May 2024
In contact-rich tasks, the hybrid, multi-modal nature of contact dynamics poses great challenges in model representation, planning, and control. Recent efforts have attempted to address these challenges via data-driven methods, learning dynamical models in combination with model predictive control. Those methods, while effective, rely solely on minimizing forward prediction errors to hope for better task performance with MPC controllers. This weak correlation can result in data inefficiency as well as limitations to overall performance. In response, we propose a novel strategy: using a policy gradient algorithm to find a simplified dynamics model that explicitly maximizes task performance. Specifically, we parameterize the stochastic policy as the perturbed output of the MPC controller, thus, the learned model representation can directly associate with the policy or task performance. We apply the proposed method to contact-rich tasks where a three-fingered robotic hand manipulates previously unknown objects. Our method significantly enhances task success rate by up to 15% in manipulating diverse objects compared to the existing method while sustaining data efficiency. Our method can solve some tasks with success rates of 70% or higher using under 30 minutes of data. All videos and codes are available at https://sites.google.com/view/lcs-rl.
@inproceedings{10611461,author={Bui, Hien and Posa, Michael},booktitle={IEEE International Conference on Robotics and Automation (ICRA)},title={Enhancing Task Performance of Learned Simplified Models via Reinforcement Learning},year={2024},month=may,volume={},number={},pages={9212-9219},keywords={System dynamics;Heuristic algorithms;Transfer learning;Stochastic processes;Reinforcement learning;Predictive models;Task analysis},location={Yokohama, Japan},doi={10.1109/ICRA57147.2024.10611461},}
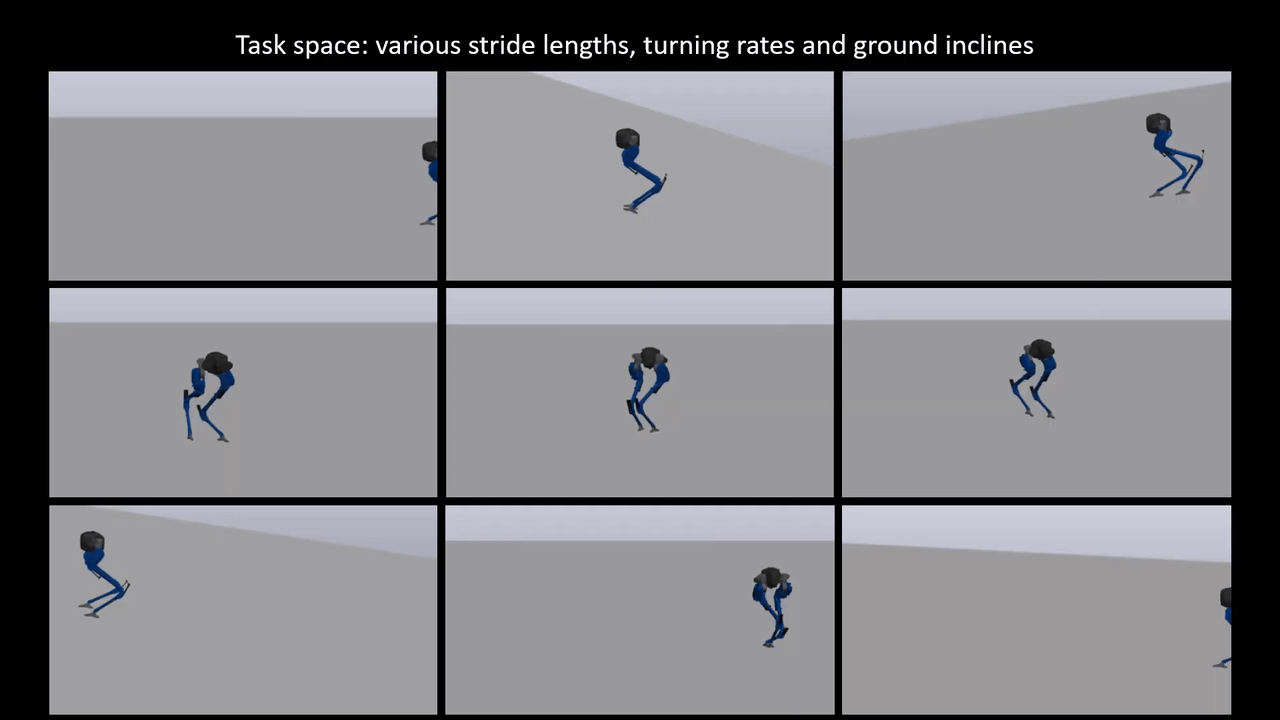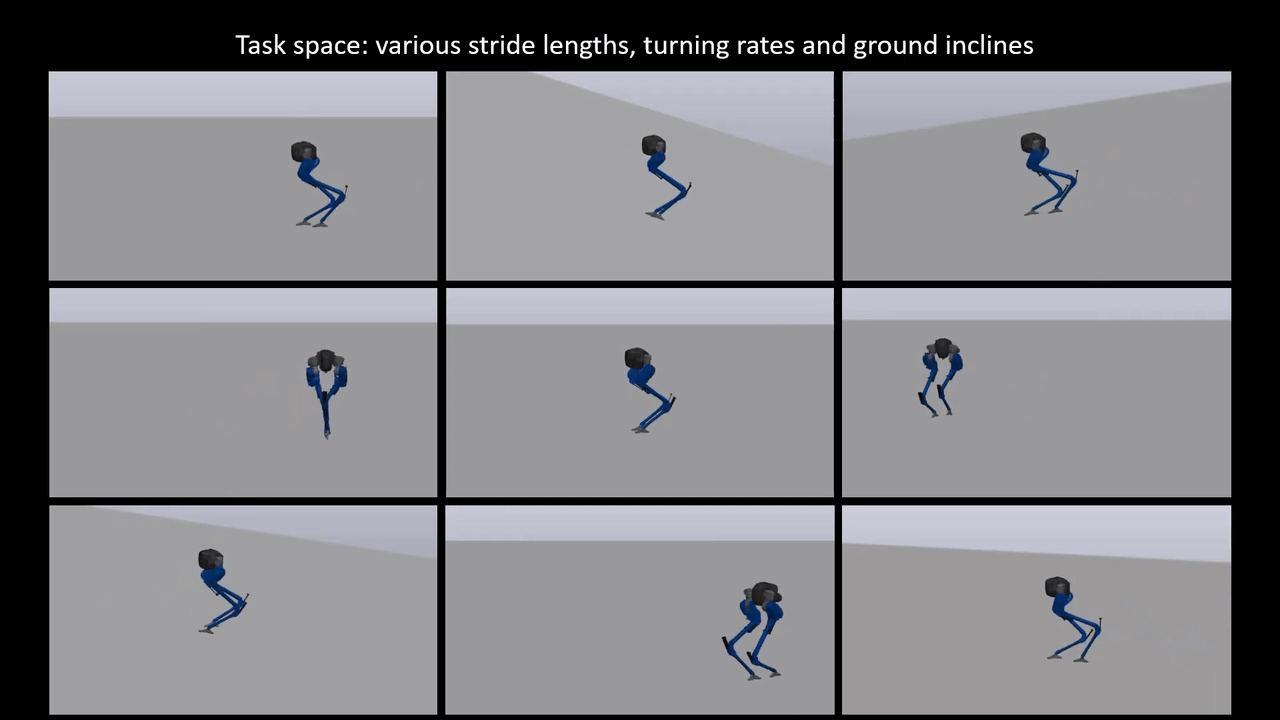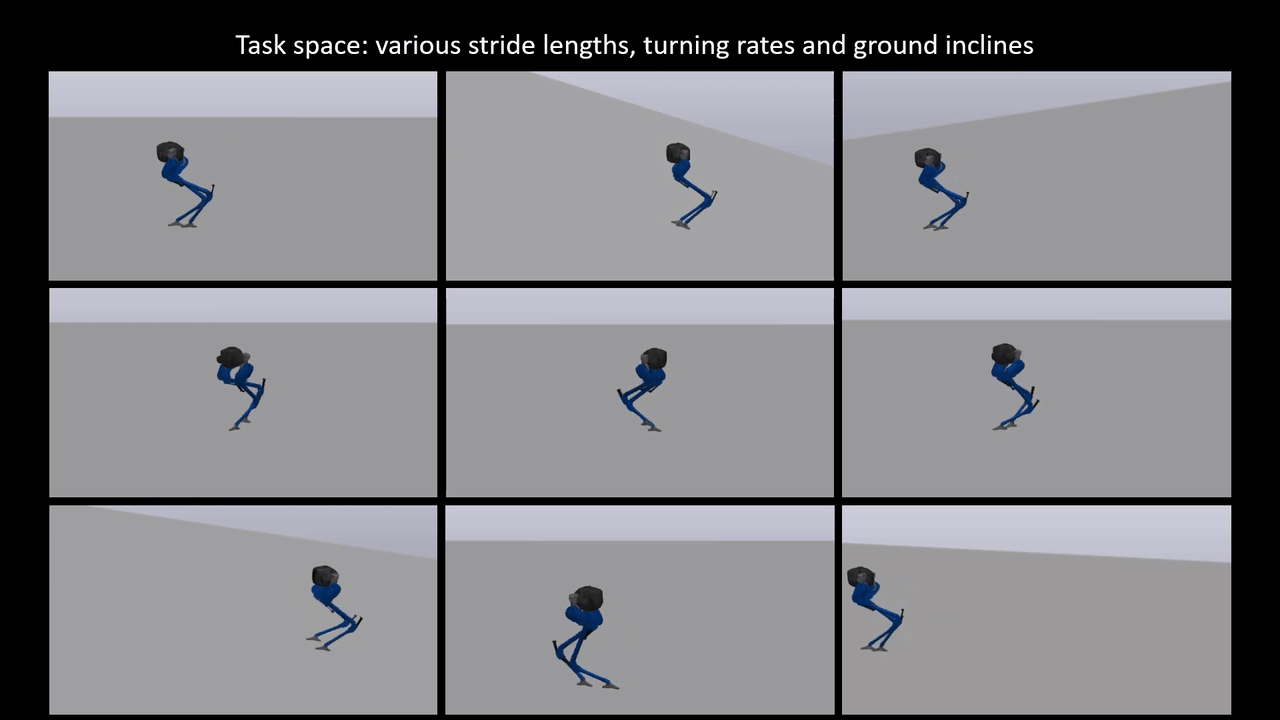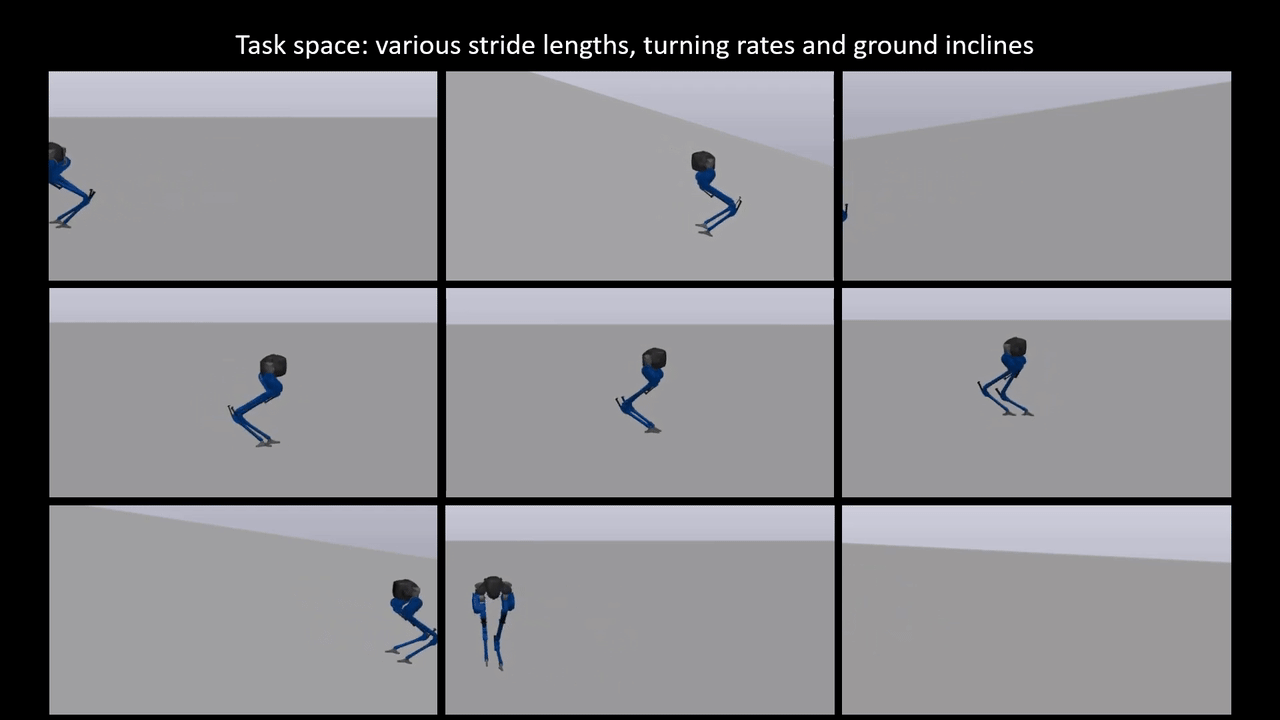
Reinforcement learning for reduced-order models of legged robots
Yu-Ming Chen, Hien Bui, and Michael Posa
In IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, May 2024
Model-based approaches for planning and control for bipedal locomotion have a long history of success. It can provide stability and safety guarantees while being effective in accomplishing many locomotion tasks. Model-free reinforcement learning, on the other hand, has gained much popularity in recent years due to computational advancements. It can achieve high performance in specific tasks, but it lacks physical interpretability and flexibility in re-purposing the policy for a different set of tasks. For instance, we can initially train a neural network (NN) policy using velocity commands as inputs. However, to handle new task commands like desired hand or footstep locations at a desired walking velocity, we must retrain a new NN policy. In this work, we attempt to bridge the gap between these two bodies of work on a bipedal platform. We formulate a model-based reinforcement learning problem to learn a reduced-order model (ROM) within a model predictive control (MPC). Results show a 49% improvement in viable task region size and a 21% reduction in motor torque cost. All videos and code are available at https://sites.google.com/view/ymchen/research/rl-for-roms.
@inproceedings{10610747,author={Chen, Yu-Ming and Bui, Hien and Posa, Michael},booktitle={IEEE International Conference on Robotics and Automation (ICRA)},title={Reinforcement learning for reduced-order models of legged robots},year={2024},month=may,volume={},number={},pages={5801-5807},keywords={Legged locomotion;Torque;Computational modeling;Reinforcement learning;Artificial neural networks;Reduced order systems;Stability analysis},location={Yokohama, Japan},doi={10.1109/ICRA57147.2024.10610747},}
Please feel free to contact me at xuanhien@seas.upenn.edu